Have you ever wondered about, or been asked to justify, the sample size used in a usability test? Well, you’re not alone! In this article we’ll explain why we are confident that six is enough, and how limiting sample size allows for iterative usability testing in place of spending your entire research budget in a big bang at a single point in the product development lifecycle.
How confident are you?
A common, and understandable, question when commissioning research with the goal of using the insights to inform business and design decisions is “how many participants are required for us to be confident in the results?” Many organisations feel more comfortable with making decisions based on quantitative data sets, leading them to query the reliability and validity of the smaller sample sizes often used in qualitative research. So, as design researchers, we need to be prepared with an answer other than “it is the industry standard”. We need to provide an answer that helps people asking this question to overcome any concerns and become advocates for the work we are doing.
It is important to recognise a significant distinction between quantitative and qualitative data, particularly in regard to design research. Broadly speaking, quantitative data is best used for measuring something, whilst qualitative data is best used for describing something. The former delivers the “what” and the latter the “why”. Both types of data have important, albeit differing and complementary, roles to play in design research. No design researcher will ever say that qualitative data reliably describes how an entire population will behave or respond, but when designed properly and interpreted appropriately, this data can be used with confidence to inform design decisions.
I heard that 5 was enough…
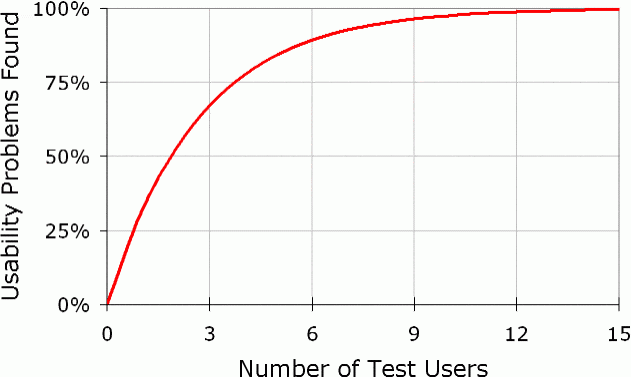
When it comes to usability testing, there has been a long-established reference to the work of Jakob Nielsen whose research, along with Tom Landauer (read the article here), identified five participants as the optimal number. Many people working as design researchers are familiar with the graph below, which illustrates that as the number of participants increases beyond five, the number (or proportion) of usability issues identified with an interface, or product, decreases. I am not going to get into the equation they employed to generate this graph, but the argument is that whilst you could involve more participants and most likely identify more issues, once the study exceeds five participants there is a diminishing return on the investment per participant. It is also likely that the major, or “show-stopper”, issues will have been identified and additional participants will reveal lower priority issues. This forms the basis of the economic argument for iterative testing, spreading available budget over multiple usability tests during the product development life cycle, rather than in one single, large-scale usability test. It is important to keep in mind that this graph, and the research it is based upon, is focussed upon discovering usability issues with a product or interface.
What are your goals?
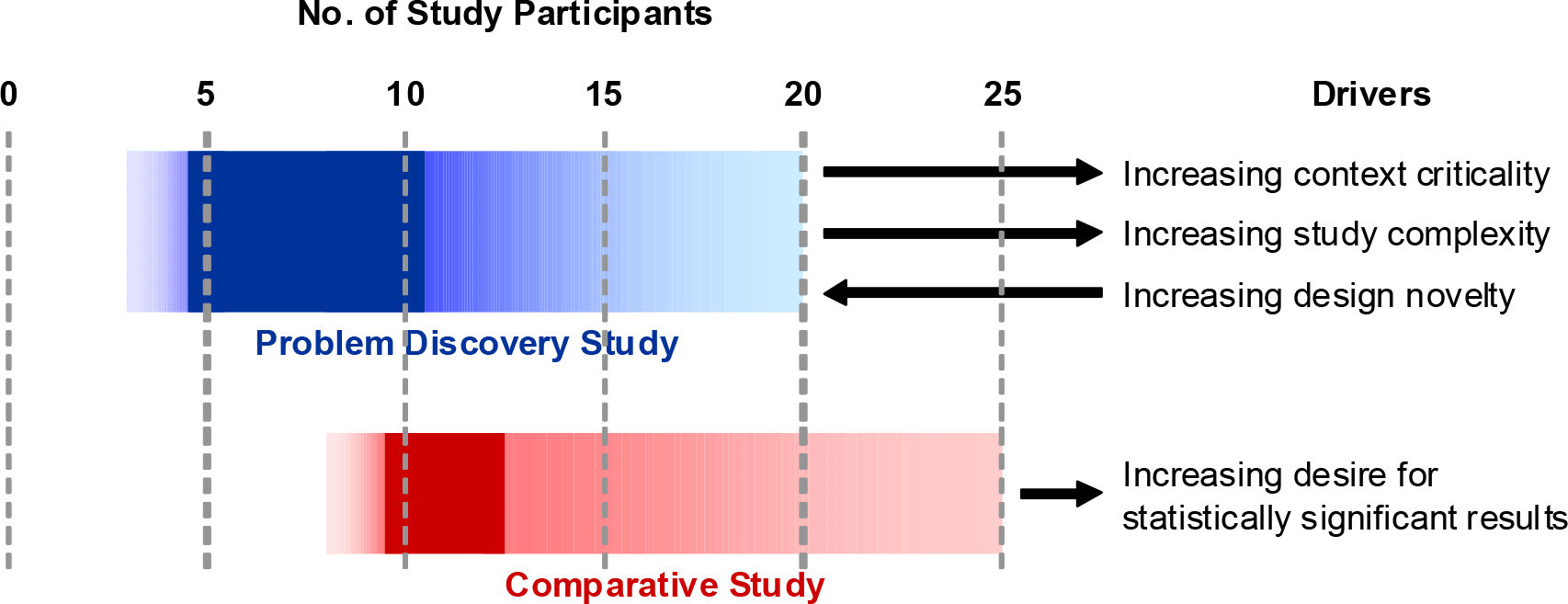
As always, there are some caveats to the rule of five participants, including the complexity of the tasks that will be attempted within the usability test, the number of audience types that need to be included, the novelty of the interface and the eventual application of the product (e.g. supermarket website vs clinical decision-making tool). These caveats, and how they relate to sample size for usability testing, are explored in depth by Janet Six and Ritch Macefield (read the article here). This article suggests that rather than adopting a one-size-fits-all approach to determining the optimal number of participants, that we should focus on a range which takes into account the complexity of tasks and novelty of an interface/product, amongst other things. They recommend a baseline of 5-10 participants for a standard usability test, but that number could go up to 20 depending on a number of factors (see graph below).
Nielsen also suggests that if there is a desire to incorporate different audience types in a usability test, who may be exposed to different tasks within the same interface or product, then allowing 3-4 participants per audience type is sufficient. Nielsen’s contention is that there is likely to be considerable overlap in observations of different audiences, given that usability issues are more likely to be related to a misalignment between expectation and actual experience, rather than differences amongst audiences. For example, the interaction design that underpins the process of submitting a form to a medical database will be the same for a General Practitioner and Specialist, it is just the nature of the questions they respond to in those forms that will vary, which is where the nuance lies.
Budget is always a factor
Ultimately, resources such as budget and timelines will have a significant impact on decisions regarding sample size for usability testing. Our collective, and individual, experience at U1 supports a minimum of six participants as a good rule of thumb for a relatively straightforward usability test on a standard website or app with a single audience type. Expanding sample size is important when the complexity of what is being tested increases and/or there are different audiences to consider. Our experience suggests that a minimum of four participants per distinct audience type allows for detection of any nuance related to that audience group, consistent with Nielsen’s recommendation, whilst also strengthening the contribution to the general insights and usability issues.
Where the goal of usability testing is to identify usability issues with an interface or product, the research of others and our experience suggests that 5-6 participants is typically sufficient. A major benefit of this “rule” relates to the economics of usability testing, allowing budget to be spread across multiple rounds of usability testing to deliver the best return on investment. In turn, allowing organisations to live the mantra of testing early and testing often.